
New AI Models in 2026: Qwen, Kimi, Opus Why Codex Changes the Game
Why Codex Changes the Game
A lot of AI coverage is still stuck in the dumbest possible frame:
who scored higher, who posted the prettier benchmark, who won the week on X.
That frame is already obsolete.
The market is no longer just sorting models by “general intelligence.” It is sorting them by where they create leverage:
- local control
- agent execution
- high-trust reasoning
- real software work in production environments
That is why the latest wave matters.
Not because one model killed the others. But because four different products are pushing four different parts of the stack:
- Qwen 3.6 27B — open-weight coding capability in a footprint that is actually operationally useful
- Kimi K2.6 — the strongest open push toward agent swarms and long-horizon execution
- Claude Opus 4.7 — premium reliability for harder, longer, more expensive work
- Codex on GPT-5.4 — proof that the battle is moving from “best model” to best execution layer
That is the real map.
Qwen 3.6 27B — the open model that gets interesting because it is usable
Qwen 3.6 27B matters for a simple reason:
it is much closer to the kind of open model that teams can actually place inside a real stack.
That is the key distinction.
A lot of open-model excitement dies on contact with operations. The model looks good in screenshots and bad in deployment reality. It is too heavy, too awkward, too expensive at scale, or too annoying to integrate cleanly.
Qwen is interesting because it pushes in the opposite direction. It suggests a more practical shape of value:
- coding relevance
- manageable size
- better infra fit
- stronger self-hosting appeal
- easier use in controlled internal workflows
That matters more than people admit.
Because in the real world, the best model is often not the smartest one. It is the one you can actually route, host, control, monitor, and afford.
That is where Qwen gets sharp.
If this class of model keeps improving, it puts real pressure on the idea that every serious engineering workflow must depend on a closed premium API.

Qwen 3.6 27B visual from the original release page.
Why Qwen matters
Qwen is not interesting because it makes closed models irrelevant. It is interesting because it improves the control-to-capability ratio.
That ratio matters a lot.
Especially if your environment already revolves around:
- Docker
- reproducible services
- internal tools
- private workloads
- routing control
- cost discipline
In that world, a model that is slightly weaker but dramatically easier to own can be the better strategic choice.
Kimi K2.6 — the boldest open bet on swarm execution
Kimi K2.6 is playing a much bigger game.
Moonshot is not trying to win on compactness. It is trying to win on ambition.
The Kimi pitch is basically this:
open-weight multimodal agentic execution at a level that starts to challenge the closed frontier players on real work, not just chat.
That is a serious claim.
The profile is aggressive:
- 1T MoE architecture
- 32B activated parameters
- 256K context
- multimodal support
- explicit long-horizon coding focus
- up to 300 sub-agents in parallel
- thousands of coordinated tool calls
This is not a “helpful assistant” story. This is an agent-runtime story.
And that is what makes Kimi one of the most interesting releases in the whole wave.

Kimi K2.6 visual from the original post, stored locally in the blog.
Why Kimi is a real signal
The signal is not one benchmark line. The signal is that open-weight systems are starting to make a real play for:
- decomposition
- coordination
- long-running execution
- parallel sub-agents
- artifact generation
- autonomous task completion
In other words, Kimi is not just competing in the old model market. It is competing in the emerging market for orchestrated AI labor.
That is a bigger deal than most reviews are willing to say out loud.
Where Kimi still needs skepticism
That said, Kimi is exactly the kind of launch where hype can outrun reality.
“300 agents” sounds great. And maybe it is great.
But the real questions are harsher:
- how coherent is the system under messy constraints?
- how much supervision does it still need?
- how expensive does it get once the workflow is real?
- how often do parallel agents create noise instead of leverage?
- how much of the magic survives outside staged demos?
So the right posture is not dismissal. But it is definitely not worship either.
The right posture is:
this may be one of the strongest open signals yet that swarm-based agent execution is becoming real — but it still has to prove itself in production conditions.
Claude Opus 4.7 — still the premium answer when the task is hard enough
Claude Opus 4.7 is easier to place.
Anthropic is not trying to be cheap. Anthropic is trying to be worth the money.
That is different.
The appeal of Opus 4.7 is not novelty. It is trust under pressure.
That means:
- long tasks
- dirty repos
- brittle constraints
- ambiguous instructions
- visual inputs mixed with text
- high cost of subtle failure
That is where stronger frontier models still matter.
Because real failure is usually not dramatic. It is quiet.
The model almost solves the problem. It sounds convincing. It writes plausible code. It forgets a constraint from 20 steps earlier. It drifts. It overclaims. It misses the edge case.
That is the kind of failure that burns time and quietly poisons trust.
Opus 4.7 matters because better performance at that boundary is worth real money.

Claude Opus 4.7 visual from the original announcement.
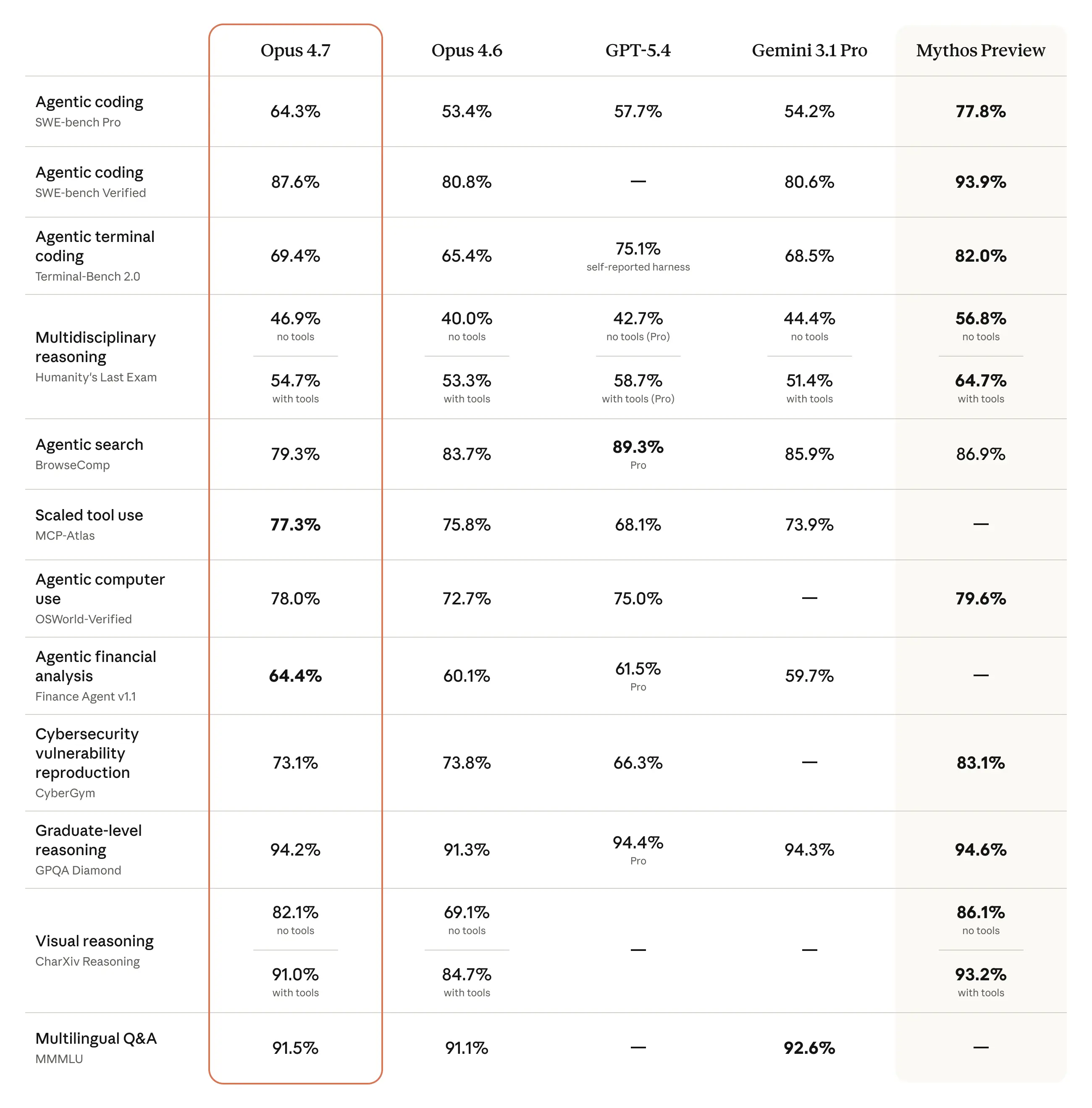
Claude Opus 4.7 capability overview from the original announcement.
Why Opus still earns its lane
The premium lane does not disappear just because open models improve.
If anything, it becomes more defined.
You use a model like Opus when:
- correctness matters more than cost
- the task is long enough for drift to hurt
- the inputs are messy
- instruction fidelity matters
- self-checking matters
- “almost right” is still expensive
That is not everyone’s workflow. But for the workflows where it is true, this tier keeps earning its place.

GDPval knowledge-work task map fits the GPT/Codex execution layer story better than the Opus reliability lane.

Local article visual for the GPT-5.4 and Codex section.
Codex — the most important shift is not the model, it is the product form
This is the part too many model roundups miss.
Codex matters because it exposes where the market is actually going.
Not toward better chat. Toward delegated execution.
That is the key shift.
Codex is not just another model badge. It now sits directly on GPT-5.4, which matters because the execution product and the frontier model are no longer separate stories.
It is a cloud software engineering agent that can work on tasks in parallel inside isolated environments, run tests, inspect a repo, make changes, and show evidence of what it did.
That changes the frame completely.
Because once you can assign scoped work to parallel agents with logs, test output, and environment boundaries, the comparison is no longer just about intelligence. It becomes about workflow throughput.
That is a different market.
Why Codex changes the game
Codex shows that the winning product is not necessarily the one that gives the smartest single answer.
The winning product may be the one that:
- takes multiple tasks at once
- operates inside the repo boundary
- runs tools instead of just talking about them
- gives verifiable outputs
- fits human review flows
- reduces context-switching for engineers
That is a much stronger product thesis than “our model is a bit better at general chat.”
In practical terms, Codex helps make one thing obvious:
the industry is moving from answer generation to work execution.
And once that shift is underway, the leaderboard mindset becomes less useful.
The actual comparison
If we stop pretending all these launches are the same category, the picture becomes clean.
Qwen 3.6 27B
Compact open-weight leverage for teams that care about control, infra fit, and cost discipline.
Kimi K2.6
Open agentic ambition aimed at swarm orchestration and long-horizon autonomous execution.
Claude Opus 4.7
Premium high-trust capability for hard, long, failure-sensitive work.
Codex
An execution-layer product built on GPT-5.4 for parallel software engineering tasks.
That is the useful comparison. Not “who won.” But what leverage each one creates.
What this means if you actually build things
If you are serious about using AI in real systems, the right question is not:
Which one is smartest in theory?
The right question is:
Which one fits the operating constraints of the work?
Choose Qwen if you care about:
- self-hosting relevance
- lower recurring cost
- infra control
- open deployment options
- strong coding value in a smaller footprint
Choose Kimi if you care about:
- agent systems
- long-horizon execution
- swarm orchestration
- multimodal workflows
- pushing open models into autonomous runtime territory
Choose Opus if you care about:
- reliability on hard tasks
- instruction fidelity
- self-checking behavior
- fewer subtle failures
- high-trust output over raw efficiency
Choose Codex on GPT-5.4 if you care about:
- parallel software work
- background execution
- repo-aware agents
- isolated task environments
- reviewable engineering output
The infra angle is not secondary — it is the whole game for many teams
This part is still under-discussed.
A model decision is also an infrastructure decision.
If your system already runs on servers, Docker, isolated services, and repeatable deployment pipelines, then the model is only one layer of the stack.
You also care about:
- observability
- environment control
- cost ceilings
- latency
- reproducibility
- security boundaries
- integration friction
That is why these launches are not interchangeable.
Qwen is attractive because it improves controllable open deployment. Kimi is attractive because it expands what open agent runtimes might become. Opus is attractive because it buys down failure on hard work. Codex is attractive because it turns model capability into actual engineering throughput.
That is the real division.
Final read
If I compress the whole picture down to one line each:
- Qwen 3.6 27B is the strongest control-and-efficiency story
- Kimi K2.6 is the strongest open swarm-and-agent story
- Claude Opus 4.7 is the strongest premium reliability story
- Codex on GPT-5.4 is the clearest sign that execution products are becoming more important than model bragging rights
That is why this wave matters.
Not because one model won the internet for a day. But because the stack is becoming more differentiated, more usable, and more real.
And that is a much better sign than another benchmark victory lap.
This review is based on the current public model and product landscape, with emphasis on practical deployment, coding workflows, agent execution, and infrastructure fit.